The Feminist Controversy in England is a cultural analytics and data visualization project. To summarize, the goal is to postulate non-binary gender terms that have been derived from texts themselves, and to demonstrate how this procedure offers an alternative method for historicizing gender.
Below you can find out the steps involved in our project.
Step 1: OCR Proofing
We started with Gina Luria Walker’s edited collection, The Feminist Controversy in England, 1788-1810, published by Garland Publishing (no longer in existence). Walker’s collection contains 44 works in a total of 89 volumes, all related to emerging feminism. Since Walker’s collection is made up of facsimiles, we have used Optical Character Recognition (OCR) software when typed transcripts were not available to prepare the texts.
Student Workers then corrected the OCR. Since we are dealing with largely eighteenth-century works, the long “s” rarely gets transcribed correctly by OCR, so this proofing is critical.


Along with errors in the OCR, Student Workers take out all of the page signatures, etc.
Corrected OCR is then uploaded into Catma.de for step two.
Step 2: Tier 1 Tagging
Catma (Computer Assisted Text Markup and Analysis) is a free and open source software hosted at the University of Hamburg, Germany. Catma is easy-to-use without any coding experience necessary.
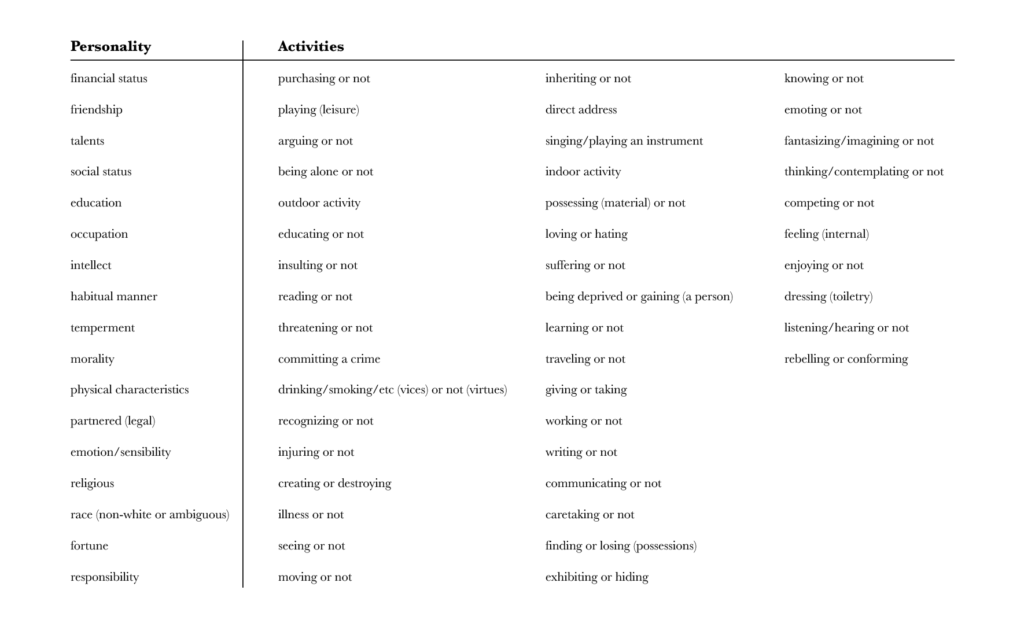
Laura Mandell and Megan Pearson developed the Tier 1 tags, listed below. We have two sets of tags: Personality and Activities. You’ll notice that the Activities are listed as “X or not” (for example, “purchasing or not”) because of the use of double negatives common in the eighteenth-century. For our purposes, it was not necessary to distinguish between purchasing and not purchasing, and this system makes it easier for our Undergraduate Student Workers to correctly tag the text, even when the prose is confusing.
The Student Coordinator and Student Workers perform the first set of tagging on all of the texts in our list.
Step 3: Tier 2 Tagging
After Tier 1 tagging is complete, the Project Manager tags character names (including narrators) and double-checks the Tier 1 tagging, adding and altering Personality and Activity tags as they see fit. They then prepare the document for our FemCon website, developed by Bryan Tarpley.
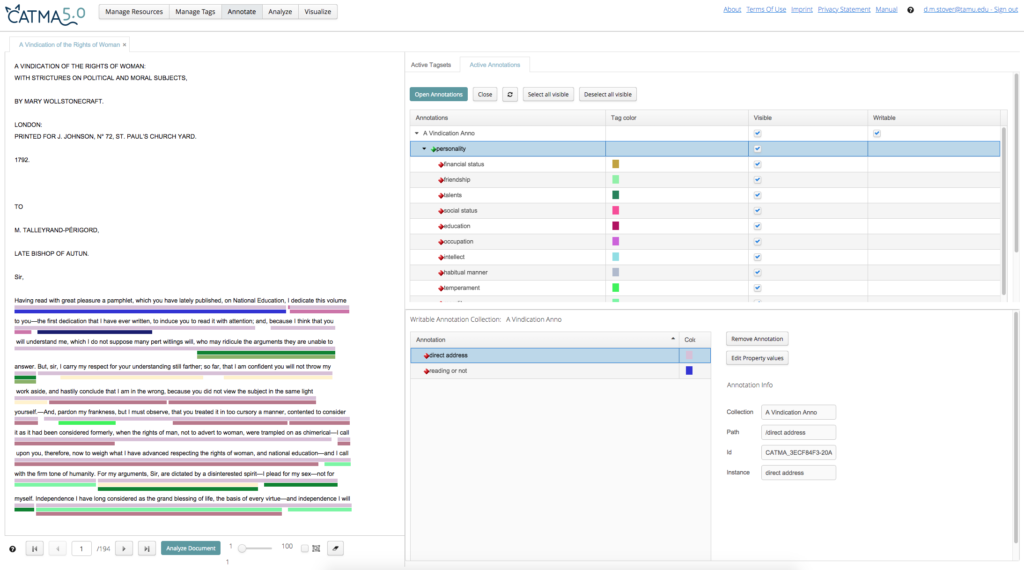
Step 4: Classify (Tier 3 Tagging)
Once the tagged texts have been uploaded to our website, Laura Mandell performs the third and final round of tagging.
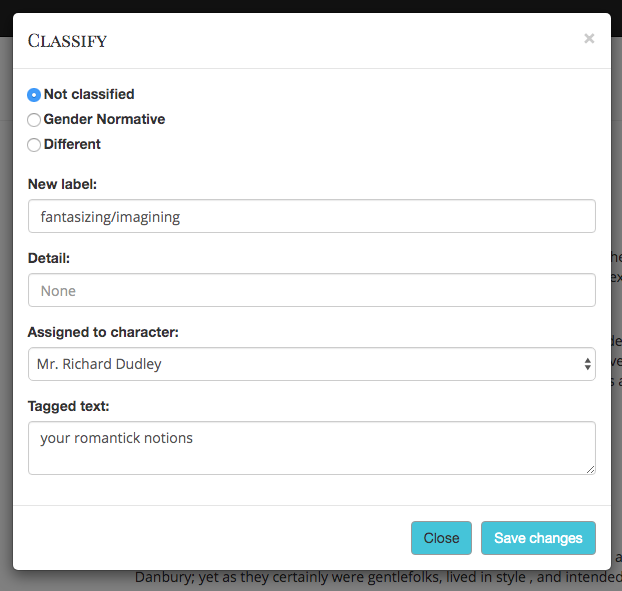
As you can see in the image above, this is where we decide whether an attribute is “gender normative” or not. If not, then we add a label to it. Caitlin Brenner and Laura Mandell developed a system for deciding what was “gender normative” for the period, with hopes of differentiating between our own assumptions of what is “gender-normative” behavior.
To develop this system, Drs. Brenner and Mandell used Mary Wollstonecraft’s Vindication of the Rights of Woman (1792) and John Gregory’s A Father’s Legacy to His Daughters (1774). Vindication clearly delineates how women were expected to behave–and then attacks those customs, including the views expressed by Gregory. We attempted to use language of the period as much as possible, so we used “In Vivo” tagging, defined by Johnny Saldaña as short phrases that come from the language of the text itself.
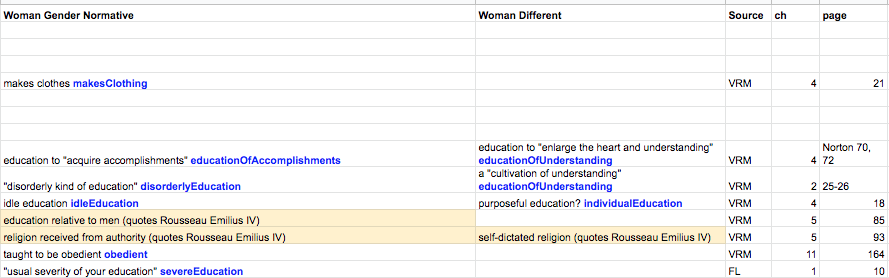
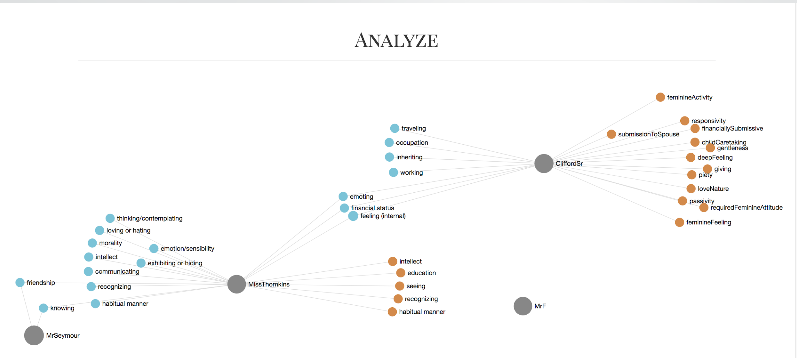
Step 5: Analyze
We just finished revamping the tags discussed in Step 4, so the results below are not accurate, but they give an idea of what it is we hope to do with this data once the project is finished.